The Journey of an SQL query

Ever wondered what happens under the hood when you issue an SQL query to a database? Well, today we dive deep into the internal working of the Oracle RDBMS to understand how an application connects to the database and what processes are followed for fetching the result of a query.
For the sake of simplicity, we will take the example of a select statement - select * from emp;. The entire process will be tackled in two parts -
- Connection
- Parsing and Execution
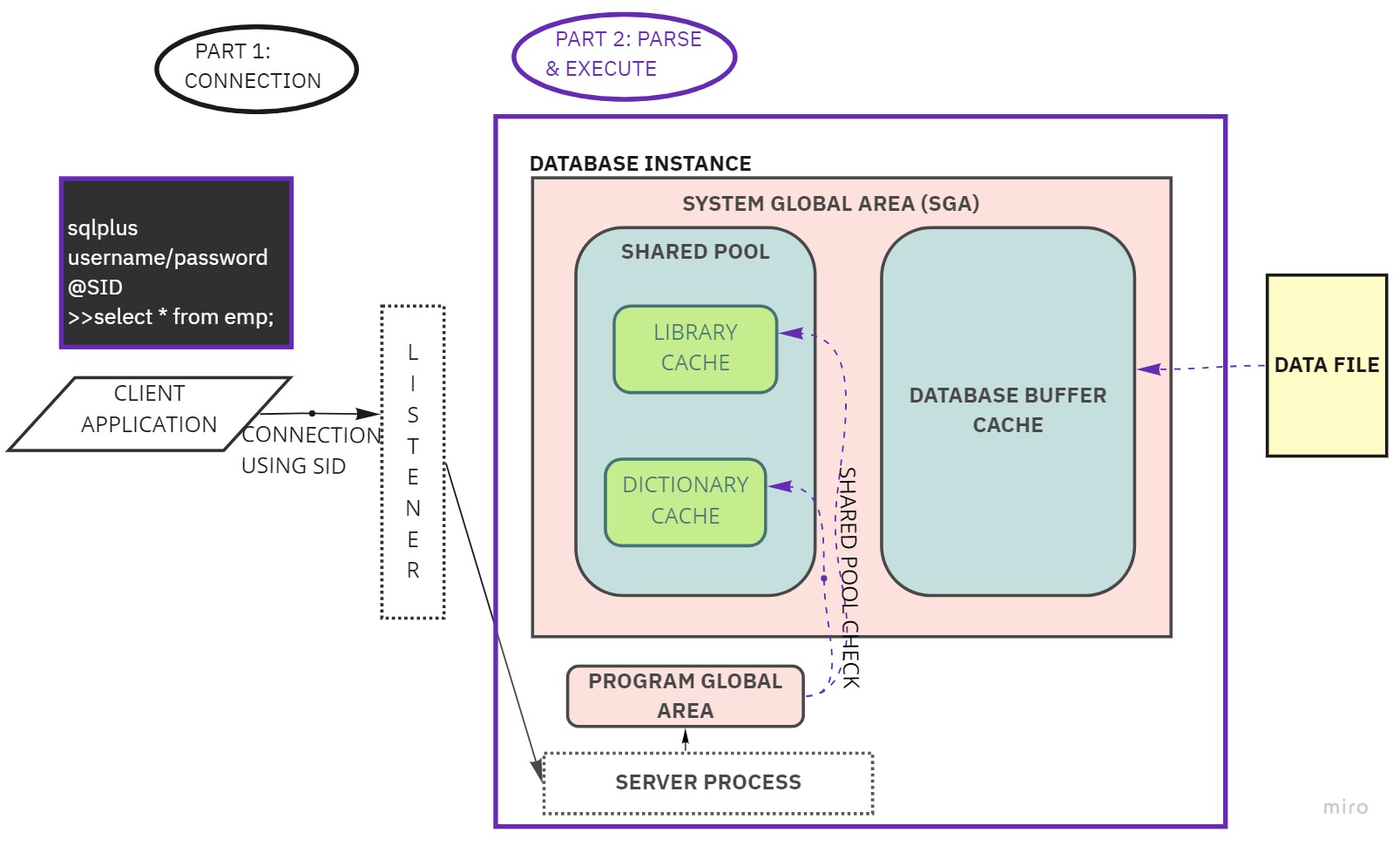 Figure 1 - Overall flow and components
Figure 1 - Overall flow and components
PART 1 - Connection
Before any magic happens in the database, the application requesting the query result needs to establish a connection with the database server. For this, it needs to supply a connection string of the following format:
sqlplus <username>/<password>@<SID or service name>
There is a process called listener as a part of the database server which runs continuously for any active database. Every database instance which starts, initially registers itself with the listener using a service name or SID. This listener process acts as a mediator between the incoming client request and the database instance. When the client requests a DB connection, the listener intercepts this request containing the service name and routes the connection to the appropriate database instance registered under the service name. It spawns a dedicated Server process for the client and passes over the client connection to this server process.
The database further authenticates the username and password supplied as a part of the connection string with the details stored in the connected DB instance. Once authenticated, the client is said to be successfully connected to the database.
Part 2 - Parse and Execute
Hereafter , there are multiple steps that take place as a part of query processing
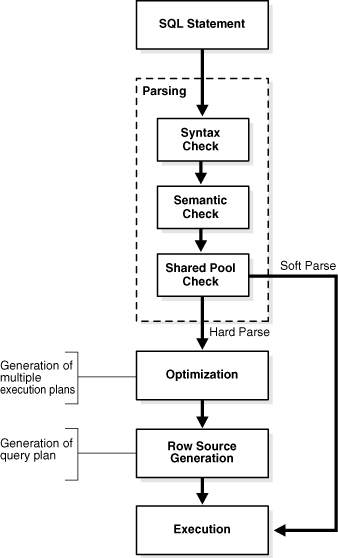 Figure 2 - Query processing steps.
Figure 2 - Query processing steps.
Image source : Oracle documentation
SQL Parsing
When an application issues an SQL statement, the application makes a parse call to the database to prepare the statement for execution. The parse call opens or creates a cursor, which is a handle for the session-specific private SQL area that holds a parsed SQL statement and other processing information. The cursor and private SQL area are in the program global area (PGA), as outlined in Figure 1.
1. Syntax Check
The first step is to check the syntax of the issued statement to validate whether proper SQL keywords/clauses are used in the proper order.
2. Semantic Check
The next step is for the DB to check the meaningfulness of the SQL statement issued. In this stage, it checks whether:
The table/tables mentioned in the query exist in the database.
The user issuing the query has access to these tables.
The columns indicated in the query are present in the table.
In case of a symantic check failure, the client can encounter an error as below:
SQL> SELECT * FROM emp;
SELECT * FROM emp
*
ERROR at line 1:
ORA-00942: table or view does not exist
3. Shared Pool Check
As the last step of the Parse phase, the database performs a shared pool check to understand whether the query that has been issued is present in the cache. The motive behind this step is to evaluate/limit the amount of resources expended towards query processing.
Every database instance consists of a component called as SGA - System Global Area which in turn houses the Shared Pool among other components.
For every query statement issued , the database generates a hash value called SQL ID using a hashing algorithm and this value is unique to an sql statement. This SQL ID is stored in a component called the Library Cache - a memory area present as a part of the Shared Pool. The Library cache stores the SQL ID computed for every SQL statement issued in the current session, along with the parsed representation of the same, so that the subsequent resource-intensive steps that go into a query's processing can be avoided if the same query is issued after a while.
Coming back to the execution flow, consider our SQL statement select * from emp; which is being issued for the first time. The database first computes the SQL ID for this query and looks it up in the library cache. Since, for our scenario the hash is not present, it results in something called as a Library cache Miss. Following this, the database needs to perform a Hard Parse to compute the code that would need to be executed using various algorithms and data structures. On the other hand, if the SQL ID had been present in the Library Cache, it would have resulted in a Library Cache Hit and a Soft Parse would have been performed. As per the flow diagram in Figure 2, the control will directly pass to the Execution step since the code is present in the Library Cache.
4. Optimisation
In the next step, the database needs to come up with the most efficient means of retrieving the data. To this end, it generates multiple execution plans for the query.
An execution plan describes a recommended method of execution for a SQL statement.
The plan shows the combination of the steps Oracle Database uses to execute a SQL statement. Each step either retrieves rows of data physically from the database or prepares them for the user issuing the statement.
Each of the candidate execution plans generated at this step represents a different method of fetching the data by using a combination of joins, access methods, index usage etc. and a cost is estimated for each step. This overall cost is a numeric value which indicates the total I/O expense estimate of fetching the data using the particular plan. Oracle uses this cost parameter to compare different plans and ultimately chooses the execution plan with the least cost as the best plan.
Following is the explain plan for our simple query select * from emp;
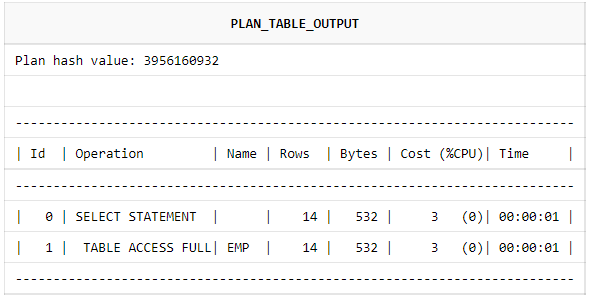
5. Row Source Generation
The optimal execution plan that is chosen in the previous step becomes the input to the row source generation software which produces an iterative execution plan that can be re-used. The row source generator produces a row source tree, which contains the following information:
An ordering of the tables referenced by the statement
An access method for each table mentioned in the statement
A join method for tables affected by join operations in the statement
Data operations such as filter, sort, or aggregation
6. Execution
In the Execution step, the database performs each operation or branch in the row source tree generated in the previous step.
In order to understand the row source tree better, let us consider the following query joining two tables emp and dept based on join condition deptno. The query filters the rows for deptno 10 only.
SELECT *
FROM emp e , dept d
WHERE e.deptno=d.deptno
AND d.deptno=10;
The following image shows the row source tree for the execution plan of the above query
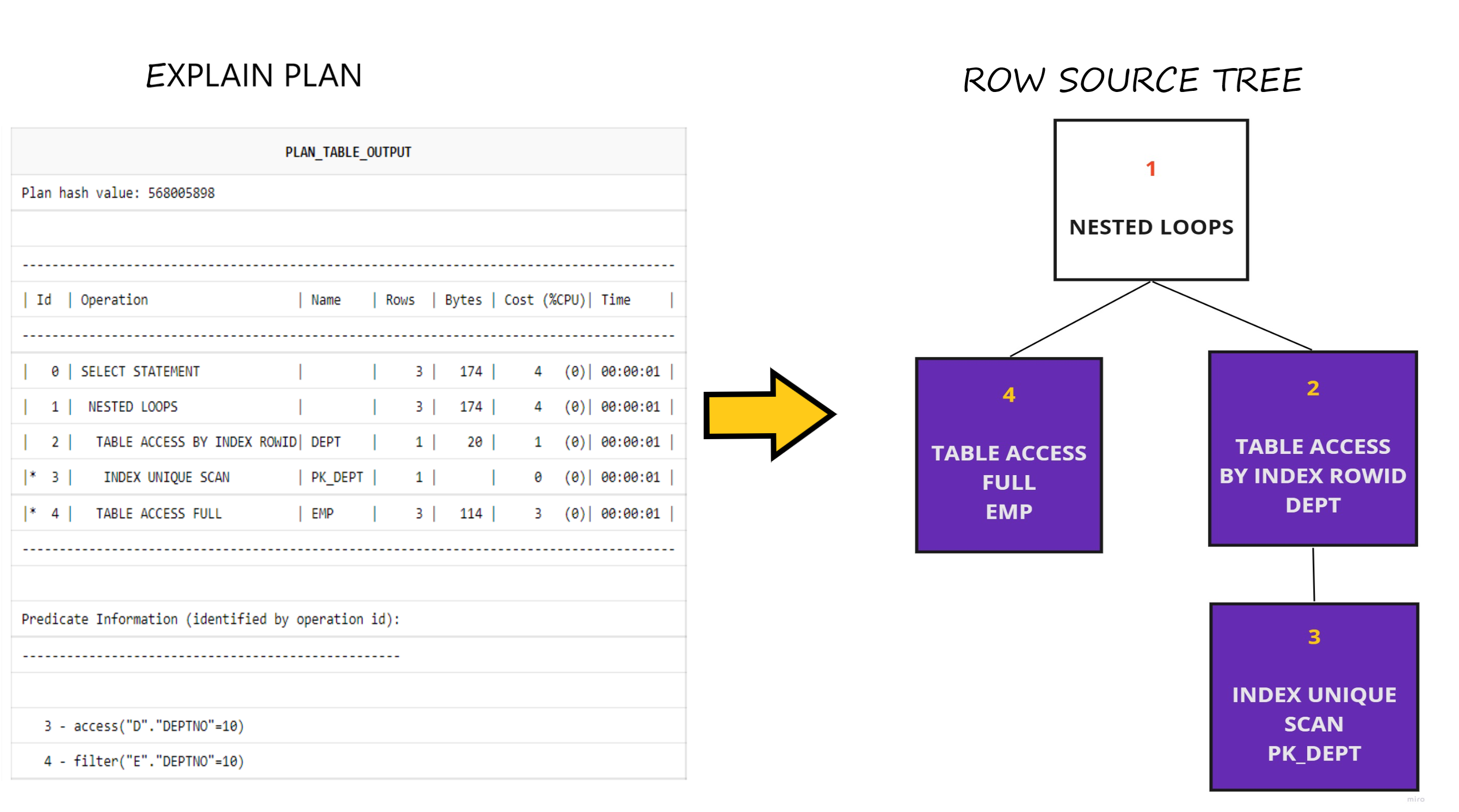
The execution plan contains a sequence of steps that will be potentially carried out by the database during query execution. The row source tree presented to the right shows the tree representation of each step or row source of the execution plan with the number in each box corresponding to the line number (Id) in the plan. The tree is constructed in a bottom-up fashion as follows:
The steps in the execution plan are executed in order beginning from the most indented to outwards. Therefore, Step ID 3 - INDEX UNIQUE SCAN is performed first. This is also the bottom-most leaf node of the Row Source Tree. From here, the tree is built upwards as per the execution plan.
The colored nodes represent the steps involving direct physical data retrieval from objects in the database like Table Full Scan / Index Range Scan.
The clear node represents the operation on the row sources i.e manipulating the rows fetched from the underlying steps. In this case, it is the NESTED LOOP join of the rows of emp and dept table.
The database starts with the index unique scan using the PK_DEPT index. This is then used to look for the corresponding rows in dept table. Parallely, the rows of the emp table are fetched completely using a Full Scan of emp table. Then the row of both the tables are joined using the Nested loop mode.
During the execution step, the database reads the data blocks from the DATA FILES present on the disk into the memory i.e Database Buffer Cache present in the SGA before sending the rows to the client application requesting the data. Finally , once all the rows are fetched the cursor opened for the SQL is closed.
Thus, after all these steps , the SQL statement query processing is said to be complete.
Hope this was a useful insight into the actual underlying processing of the database during query execution.
Information Source: Official Oracle Documentation



