


Python has some pretty fantastic libraries when it comes to extracting and manipulating data from various sources and file formats. Today we will look at how to extract tabular data present in a pdf file using a popular python library Camelot. There are a few other libraries like PyPDF2 which are capable of reading PDF files. But, for PDF files containing tabular data, Camelot provides an efficient mechanism to access the content by loading the table data into a pandas DataFrame which makes the data easier to analyze, manipulate and render.
In this post, we will simply extract a table from a pdf file and render it on an html page using Python flask.
1. Installing the required libraries and dependencies
1.1 Installing Camelot
The first step is to install the camelot library. If you have the pip
installer, then you can simply run the following command on the command-line
terminal
pip install "camelot-py[base]"
There are other ways to install camelot , using conda or from the source code of the git repository, which are explained here.
1.2 Ghostscript dependency
Once camelot is installed, you can optionally install the Ghostscript utility to enhance the usability of camelot. It is optional because camelot can be executed in 2 flavours - stream and lattice (which we will understand in the later sections) and the Ghostscript utility is a pre-requisite for the lattice mode. In general, it is a good idea to install this as there is a very good chance you may be using the lattice mode for table extraction.
Download and install Ghostscript from this link
Add the path of the executable and the lib folder to the PATH environment variable of your system.
For eg, if you are installing on Windows and Ghostscript has been installed in directory C:\Program Files (x86)\gs, then add the following paths to the PATH environment variable:
C:\Program Files (x86)\gs\gs9.55.0\bin
C:\Program Files (x86)\gs\gs9.55.0\lib
Note: In case you are installing Ghostscript for Windows, it is a good idea to download and install the 32 bit version of the utility, irrespective of whether your OS is 64-bit or 32-bit, as there seem to be some issues while detecting the 64-bit executable at run-time.
1.3 Installing Pikepdf - Optional for password encrypted files
This is again an optional installation. Pikepdf is a python library that is based on QPDF which is, in turn a C++ based command line tool developed for PDF file manipulation and transformation.
The only reason the library features in this tutorial on Camelot is because of it's ability to decrypt all types of encrypted PDF files. Though Camelot can read and interpret password protected files, its capabilities are limited. As per Camelot's official documentation:
Camelot only supports PDFs encrypted with ASCII passwords and algorithm code 1 or 2. If your PDF files are using unsupported encryption algorithms you are advised to remove encryption by using third party tools like QPDF.
So, in case you are dealing with encrypted PDF files, it is a good idea to install PikePDF as it supports a wide range of encryption algorithms.
pikepdf can be installed using the following command:
pip install pikepdf
2. Reading the PDF file.
Once all the required libraries and modules have been installed, we will proceed to write the code for reading and rendering the PDF data. Consider the following snapshot of one of the tables in our pdf file:
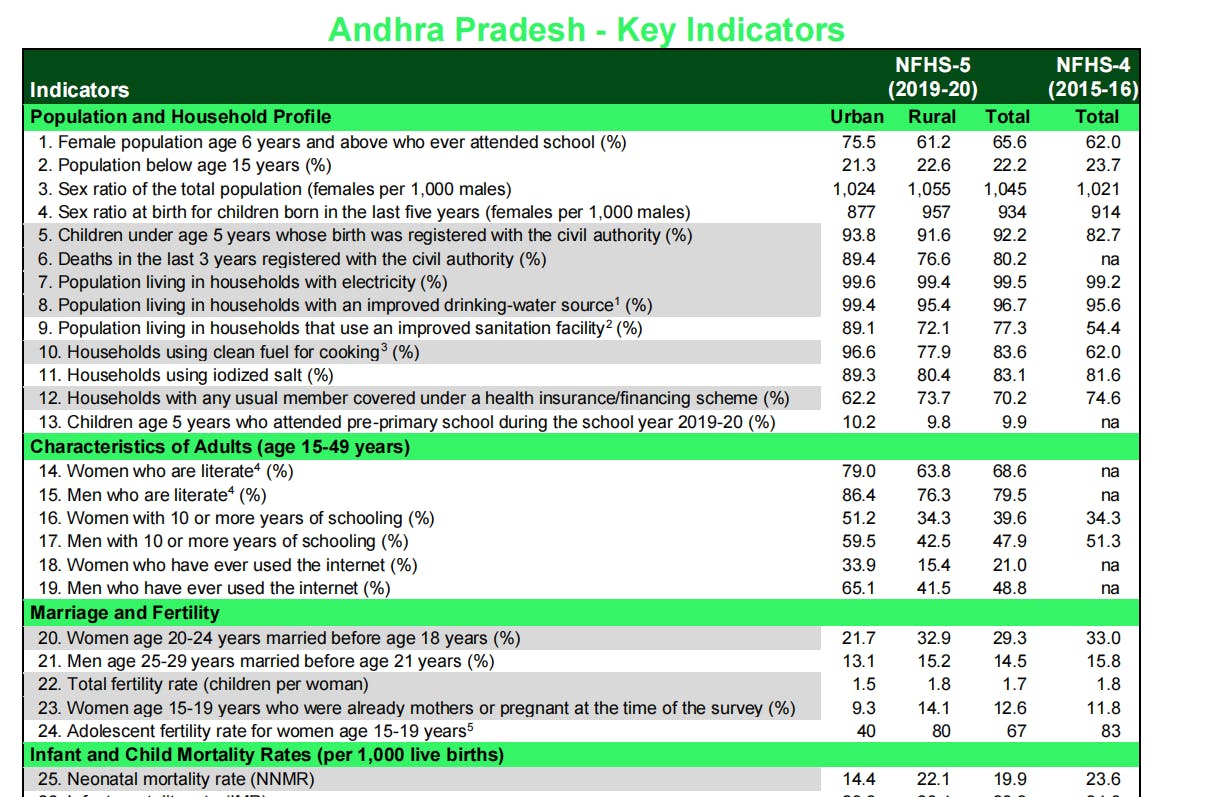 Figure 1 - Table in PDF file NFHS-5_Phase-I.pdf to be extracted
Figure 1 - Table in PDF file NFHS-5_Phase-I.pdf to be extracted
This is an excerpt from the public document on National Family Health Survey 2019-20 and shows the statistics for the state of Andhra Pradesh, India. This table features on page 17 of the PDF file and is the table that we will be attempting to extract.
2.1 Decrypting the file
This step is only necessary for PDF files that are password-protected. Following is the Python flask code for decrypting the file using pikepdf.
import pikepdf
pdfPath1="/path/for/file/NFHS-5_Phase-I.pdf"
with pikepdf.open(pdfPath1, password="<input password for file>") as pdf:
newFile="New_"+file
pdfPath1=pdfPath+"/"+newFile
pdf.save(pdfPath1)
The above code decrypts the PDF file passed in the variable pdfPath1 using the password passed as parameter to the pikepdf.open() function. It then saves the content of the PDF in a new password-less PDF file pre-fixed with New_.
2.2 Loading the table into a DataFrame
We will now use camelot to read the table as follows:
import camelot
import pandas as pd
table_data=camelot.read_pdf(pdfPath1, flavor="stream", pages='17-20')
table_df = pd.DataFrame(table_data[0].df)
print(df)
The read_pdf() function takes the following three arguments in the above example (though there are many more possible arguments):
- <filename> - pdfPath1 - Variable containing the PDF file-name with path
flavor - The flavor determines the table parsing technique. There are two possible values for flavor - Lattice and Stream.
- Stream - Can be used to parse tables that have no clear line edges to demarcate the different rows and columns and instead rely on whitespaces between cells to simulate a table structure. The stream method guesses the table area by grouping characters on a page and the uses the spacing between words in each row to determine columns. The PDF snapshot given above that we are trying to parse is a good example of this use-case where there are no proper lines segregating the columns.
- Lattice - Lattice is the default flavor and uses a more deterministic approach to identify tables. It is ideal for tables which are of the conventional format with clear line segments to determine table edges and separate rows and columns. This mode converts the PDF page to an image using the Ghostscript utility and processes the same to get horizontal and vertical lines to determine rows and columns to extract the table data. The following PDF table snapshot is a good example of this category:
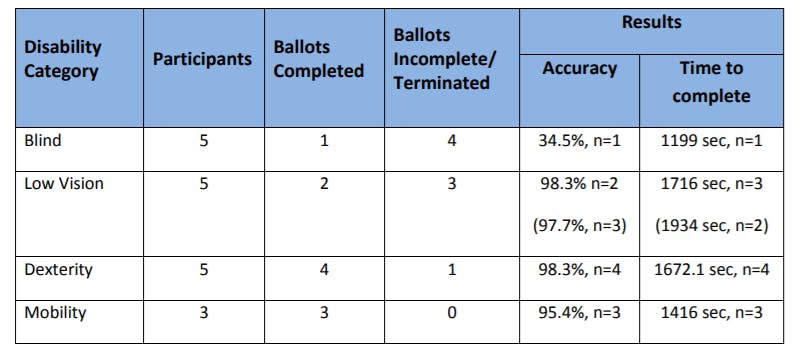 Figure 2 - A sample table in a PDF file separated by lines - a candidate for lattice method
Figure 2 - A sample table in a PDF file separated by lines - a candidate for lattice method
- pages - This parameter is used to specify the page range to be read.
The camelot.read_pdf() returns a camelot.TableList object - which contains a list of all the extracted tables in the pdf (or range of pages mentioned). Each table can be accessed by indexing this object and the .df is the object property allows the table to be accessed as a pandas DataFrame. Hence the table_data[0].df in the above code snippet accesses the first table in the PDF which is the one in Figure 1, as a DataFrame.
3. Manipulating the data in the DataFrame
Hereafter, you are free to read the data from the DataFrame as per your requirements for data analysis. In this article, we will attempt to render the extracted DataFrame as an HTML table.
For this, we can either pass the entire DataFrame to the html file and render it using Jinja2 template or we can convert the DataFrame data into a list and then pass it to the html file. We will proceed with the second option.
table_df = table_df.to_dict(orient='list')
table_df = list(table_df .values())
return render_template('index.html',data=table_df)
The table_df generated above is a list of lists i.e list of items in which each individual item is a list of values in a particular column of the extracted table. Following is the output of print(table_df) condensed to show a few sample values for brevity and understanding.
[['', 'Indicators', 'Population and Household Profile', '1. Female population age 6 years and above who ever attended school (%)', '2. Population below age 15 years (%)', ...], ['', '', 'Urban', '75.5', '21.3', ...], ['NFHS-5', '(2019-20)', 'Rural', '61.2', '22.6', ...], ['', '', 'Total', '65.6', '22.2', ..],
['NFHS-4', '(2015-16)', 'Total', '62.0', '23.7', '1,021',...]]
We pass this as a parameter to the render_template() flask function to render this in the index.html page.
The complete .py code for the implementation is :
mainPDF.py
from flask import Flask, request, jsonify,render_template,send_from_directory
import camelot
import pandas as pd
import pikepdf
app = Flask(__name__)
@app.route('/' , methods = ['GET','POST'])
def first():
pdfPath1="/path/for/file/NFHS-5_Phase-I.pdf"
table_data=camelot.read_pdf(pdfPath1, flavor="stream", pages='17-20')
table_df = pd.DataFrame(table_data[0].df)
table_df = table_df.to_dict(orient='list')
table_df = list(table_df.values())
return render_template('index.html', data=table_df)
4. Rendering the table
Following is the code for index.html file mentioned above to render the table_df list as a table using the Jinja2 template.
<html>
<body>
<div class="table-wrapper">
<table class="fl-table">
{% for ind in range( data[0] | length) %}
<tbody>
<tr>
{% for inner in range(data | length) %}
<td>{{ data[inner][ind] }}</td>
{% endfor %}
</tr>
{% endfor %}
</tbody>
</table>
</div>
{% endif %}
</body>
</html>
The above code renders the column oriented list passed to the file as a series of html table rows. After some css styling, the rendered html page looks something as follows:
 Figure 3 : The final table rendered in html
Figure 3 : The final table rendered in html
Hope this was a helpful tutorial in understanding the use of Python to read PDF files.
Camelot information source - Camelot documentation