


Transitioning to a NoSQL database can be daunting for folks who have spent the better part of their coding journey dabbling in RDBMS systems (like yours truly :)). Which is what inspired this article. If you are one of those who can whip up an SQL query without batting an eyelid but are intimidated by the mere thought of replicating the concepts, mainly those involving aggregations and analytics, to a NoSQL database like MongoDB, then stick on, you might just find something useful here.
Introduction to MongoDB collections
Before we jump to the syntax and code, let us familiarize ourselves with the idea of collections in MongoDB. Being a NoSQL document database, a collection in MongoDB is conceptually similar to a table in RDBMS - in the sense it is a grouping together of similar documents just as a table is group of rows having the same structure.
A document in the most basic building block of data in MongoDB. It is a set of key-value pairs written using the JSON notation - where the value can be either a single value, an array of values or another embedded document. Ideally, in a collection, all the documents have the same keys (fields) with the respective values differing across documents.
Aggregation
Aggregation is one of the most used SQL constructs, which is achieved using the GROUP BY clause. A similar $group operator exists in MongoDB which performs aggregation.
The Scenario
Let us consider the following EMPLOYEE table structure in the left hand column of the below figure. Our goal is to find the total salary of all the employees for each department.
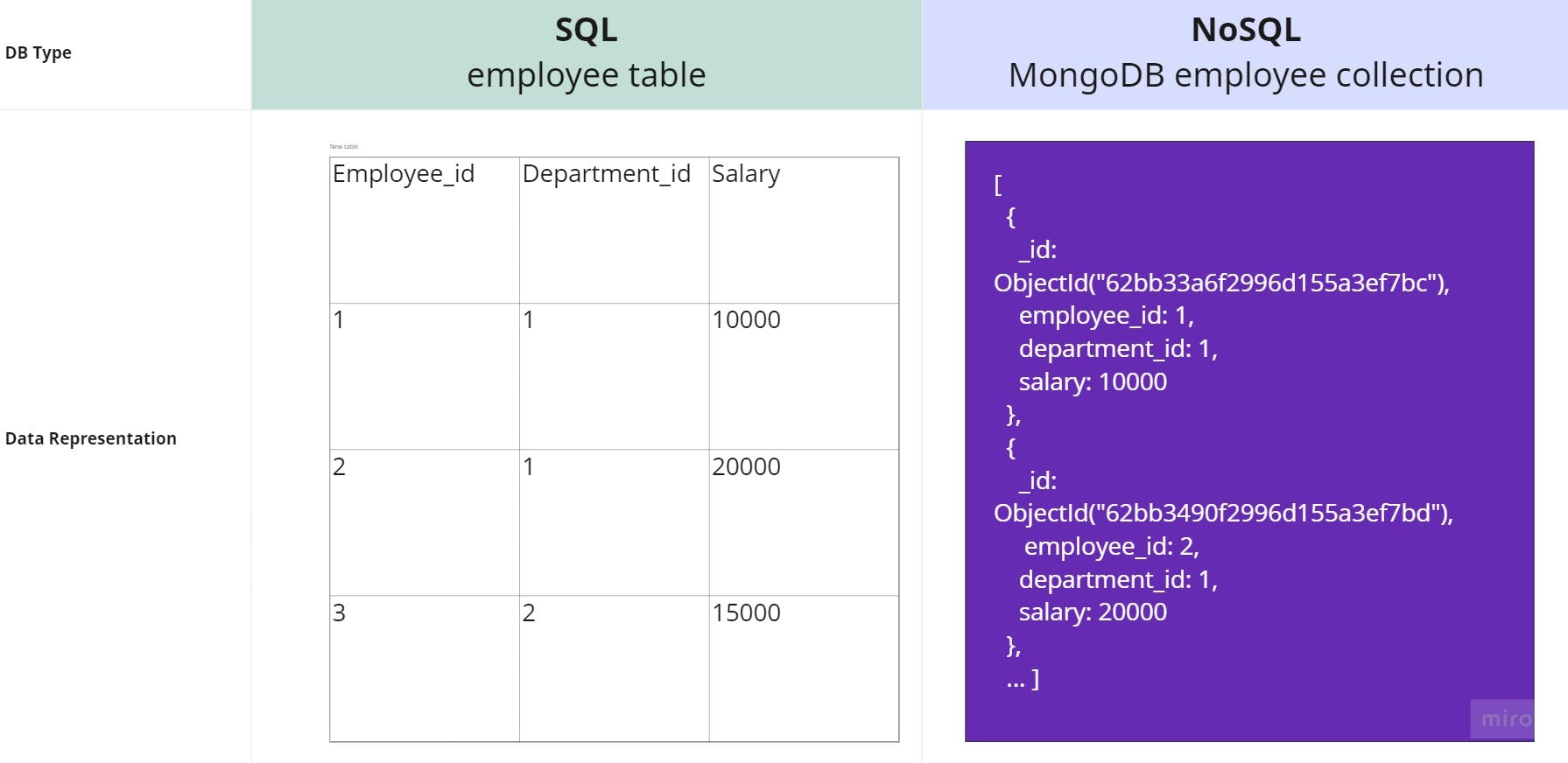 Figure 1 - The sample table and MongoDB collection for understanding aggregation
Figure 1 - The sample table and MongoDB collection for understanding aggregation
The SQL approach
The solution is to use a simple query as follows to get the department-wise sum by performing a group by operation.
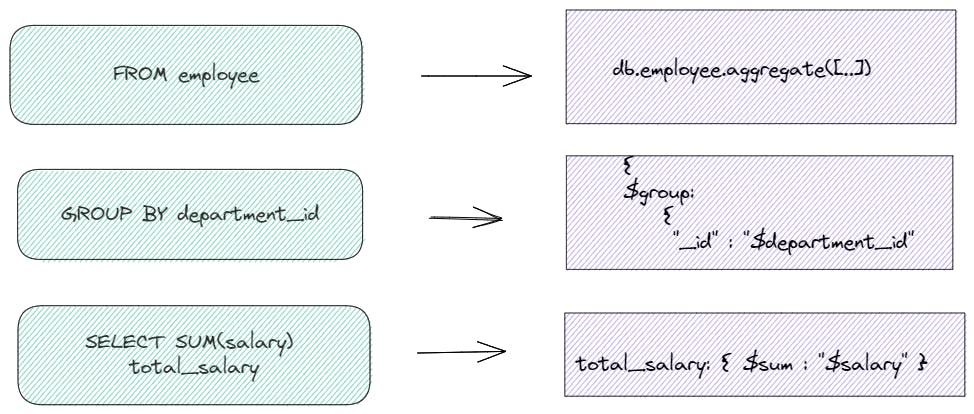
SELECT department_id, sum(salary) total_salary
FROM employee
GROUP BY department_id
which results in the following output :
| Department_id | Total_salary |
| 1 | 30000 |
| 2 | 15000 |
The MongoDB approach
The collection that we are going to use will be the one shown in the right half of the Figure 1. We have three fields employee_id, department_id and salary similar to the table we saw before. Use the $group operator using the following syntax for the solution.
db.employee.aggregate([
{ $group:
{ _id : "$department_id",
total_salary: { $sum : "$salary" }
}
}
])
Let's break down the syntax:
db.employee.aggregate --> Here we have applied the aggregate method on the employee collection to indicate that we wish to perform an aggregation operation on the documents of the collection. The aggregate method can take a sequence of such aggregation operations to be performed in stages, which is why the first parameter is an array []
$group --> This operator is used for performing the group by operation - It separates the documents of the employee collection into groups based on the key or field specified by the _id field in the following line (department_id in our case).
We can also specify any additional fields to be displayed in the output which can be set using accumulator expressions like sum, average, count etc. In the above example, the linetotal_salary: { $sum : "$salary" } indicates that a new field total salary is required which will be the sum of all the salary fields in the groups formed in the previous step based on the department_id field.
The output in MongoDB is as follows:
[ { _id: 1, total_salary: 30000 }, { _id: 2, total_salary: 15000 } ]
SQL to MongoDB query mapping
Here is a helpful image showing the mapping between the SQL query and MongoDB syntax that we just wrote :
More Accumulator Expressions
The example discussed above uses the $sum accumulator expression. Apart from this, there are other helpful expressions like $count for returning the count of documents in a group, $avg for returning the average of values in a group , $first and $last for returning values from the first and last document in a group, to name a few.
One important function in Oracle SQL called LISTAGG helps in simply displaying a delimiter separated list of values in a group instead of applying any arithmetic or logical expression. The closest operator that we have to this in MongoDB is the$addToSet accumulator operator that can be used to generate an array of unique expression values for each group.
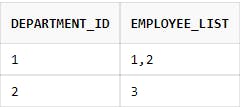
Consider the following SQL query for returning the list of employee ids in each department from the above EMPLOYEE table.
SELECT department_id, LISTAGG(employee_id,',') WITHIN GROUP (ORDER BY employee_id) employee_list
FROM employee
GROUP BY department_id;
Which results in the following output:
The equivalent query in MongoDB would be :
db.employee.aggregate([
{ $group:
{ _id : { "department_id" :"$department_id"},
"employee_list" : { $addToSet: "$employee_id" }
}
}
])
Which results in the following output.
[
{ _id: { department_id: 1 }, employee_list: [ 1, 2 ] },
{ _id: { department_id: 2 }, employee_list: [ 3 ] }
]
The resulting employee_list field contains a array of employee_ids in each department similar to the comma-separated values generated by the SQL statement.
Now, since the foundation has been laid, let's move onto the next construct.
Joins and Lookups
Joins is a common operation used in SQL for joining the information spread across two or more related tables based on a common column value. We can face a similar need to merge the documents stored across multiple collections in MongoDB, which is achieved using the lookup operator as we will examine in detail later.
The Scenario
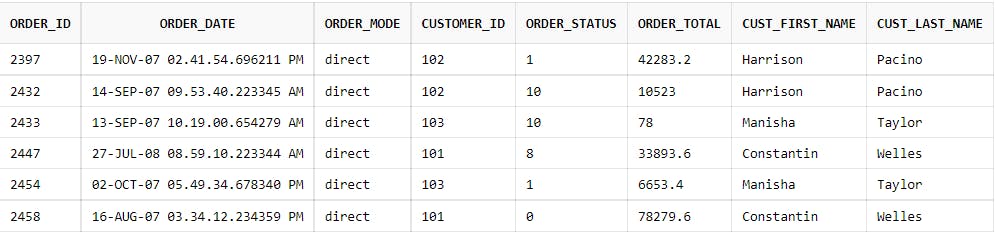
Consider the following two tables - CUSTOMERS and ORDERS in RDBMS. The CUSTOMERS tables shows the details of all the customers like first name, last name, date of birth and email id whereas the ORDERS table shows the orders placed by each of the customers so far. The customer_id foreign key in the ORDERS table is used to establish a many-to-one relation to the CUSTOMERS table.
 Fig - CUSTOMERS table
Fig - CUSTOMERS table
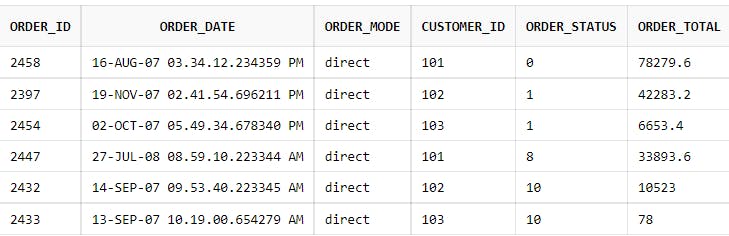 Fig - ORDERS table
Fig - ORDERS table
The SQL Approach
In order to fetch the customer first name and last name for each order against the customer in the ORDERS table, we will have to issue a query joining the 2 tables as follows :
SELECT order_id, order_date, order_mode,
o.customer_id, order_status, order_total,
c.cust_first_name, c.cust_last_name
FROM orders o, customers c
WHERE c.customer_id=o.customer_id;
The output is as follows with the customer first name and last name columns printed:
The MongoDB approach
Now here is where things get a little tricky. The lookup operator in MongoDB performs a left outer join from the input collection to another collection (referred to as joined collection) to filter in the matching documents based on the join field. To each input document, the $lookup stage adds a new array field whose elements are the matching documents from the "joined" collection. To understand this, we will consider the following customers and orders collections in MongoDB which are analogous to the CUSTOMERS and ORDERS tables described above.
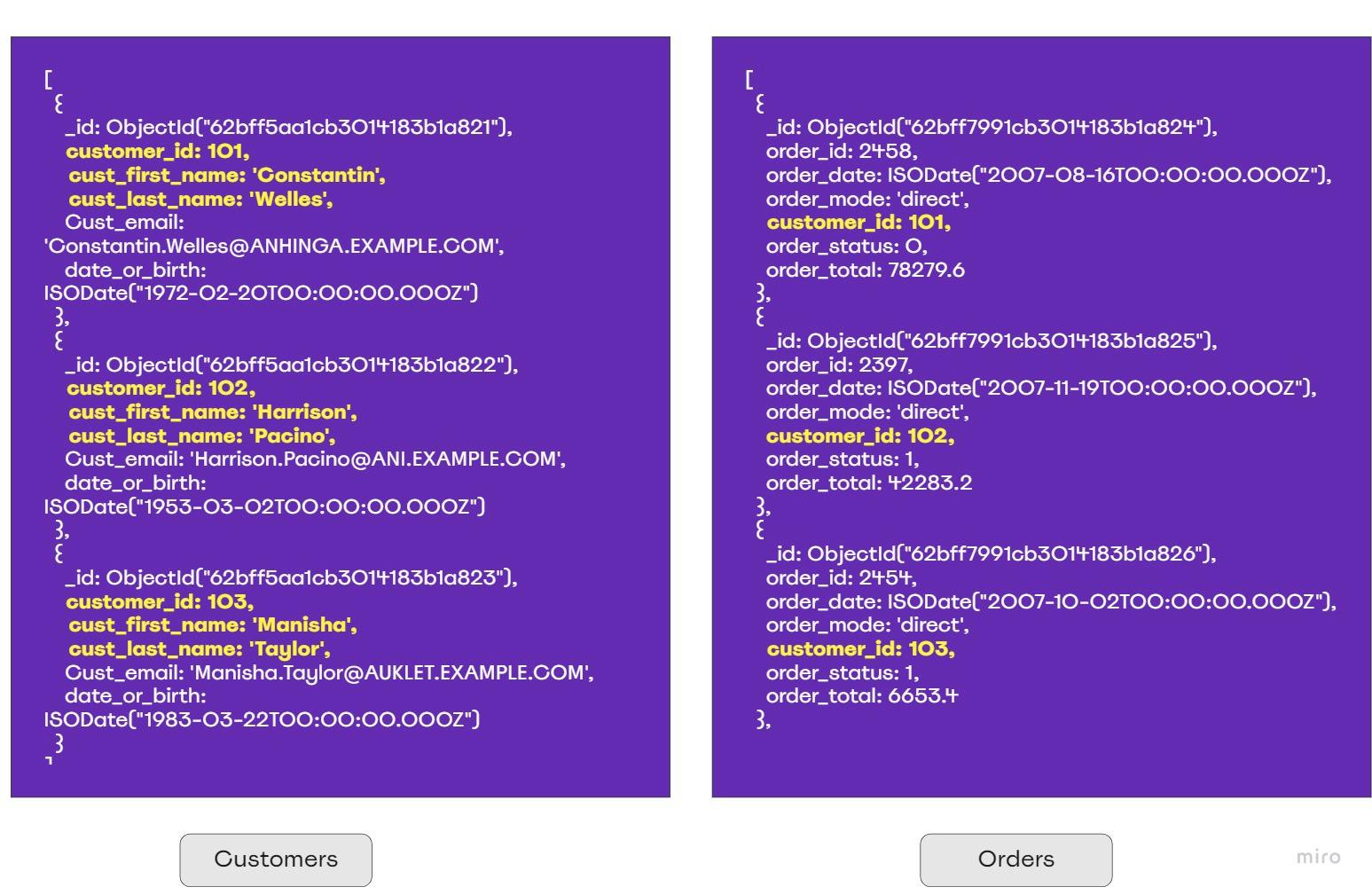
As we want the query result to contain the first name and last names of the customers belonging to a specific order, we will drive off the orders collection as follows:
db.orders.aggregate([
{
$lookup:
{
from: "customers",
localField: "customer_id",
foreignField: "customer_id",
pipeline : [ { $project:
{
_id: 0,
"cust_first_name": 1,
"cust_last_name": 1
}
}
],
as: "customer_details"
}
}
])
Let's break-down the query:
db.orders.aggregate - Tells the database what the input collection will be - the orders collection in our case.
from- To specify the collection to perform the join with. In our example, this will be the customers collection.
localField - To specify the name of the field in the input collection based on which you want to match the documents for the join.
foreignField- To specify the name of the field in the from collection that will be matched for equality with the one specified in localField. In our example, both the fields will be customer_id as we want to perform the join based on the customer_id field in both the collections.
pipeline - This is an optional field which can be used to specify any additional join or filter conditions. Here, we have used it to project only the cust_first_name and cust_last_name fields of the joined customers collection in the output, by placing a 1 after the field names to indicate that they need to be present in the output.
(Note - All the other columns of customers will be suppressed by default in the $project stage, except for the _id field which needs to be suppressed explicitly using a 0.)
as - This is used the specify the name of the new field which will have the list of matching documents in the joined collection as a part of the output.
Query Output
[
{
_id: ObjectId("62bff7991cb3014183b1a824"),
order_id: 2458,
order_date: ISODate("2007-08-16T00:00:00.000Z"),
order_mode: 'direct',
customer_id: 101,
order_status: 0,
order_total: 78279.6,
customer_details: [ { cust_first_name: 'Constantin', cust_last_name: 'Welles' } ]
},
{
_id: ObjectId("62bff7991cb3014183b1a825"),
order_id: 2397,
order_date: ISODate("2007-11-19T00:00:00.000Z"),
order_mode: 'direct',
customer_id: 102,
order_status: 1,
order_total: 42283.2,
customer_details: [ { cust_first_name: 'Harrison', cust_last_name: 'Pacino' } ]
},
{
_id: ObjectId("62bff7991cb3014183b1a826"),
order_id: 2454,
order_date: ISODate("2007-10-02T00:00:00.000Z"),
order_mode: 'direct',
customer_id: 103,
order_status: 1,
order_total: 6653.4,
customer_details: [ { cust_first_name: 'Manisha', cust_last_name: 'Taylor' } ]
},
...
]
The output has been truncated for the sake of brevity, but we can clearly see how all the columns of the orders collection have been displayed along with a new field "customer_details" which has the first and last names of the customers corresponding to the respective customer_id field.
SQL to MongoDB query mapping
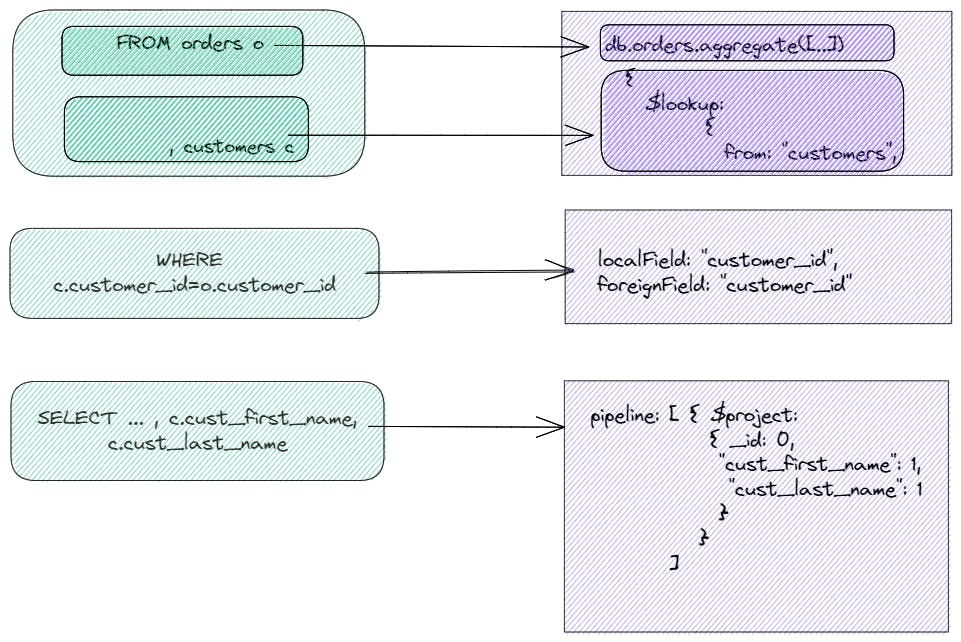
The following image maps the SQL constructs to their equivalent MongoDB operators:
That brings us to the end of this piece. This article attempts to provide just a glimpse into the world of MongoDB queries and draw a correlation to the widely popular and intuitive SQL language. Hope this helped in some way in easing your journey towards learning MongoDB or provided some motivation to pick it up soon :)
Source and Additional Reading: MongoDB Documentation