




We often query the database to gather insights and analyse relations between the different entities. But how frustrating is it when a simple SQL statement takes ages to fetch the desired results , keeping you as a data analyst/new developer guessing, or worse, degrading the application performance in case of a production environment.
Through this article, we try to make sense of why some queries perform slower than expected and the simple measures we can take to speed things up.
Just a little disclaimer before proceeding - Though the syntax specified for the queries are for Oracle SQL database (because that's where the bulk of my experience lies), the concepts can be extrapolated to apply to any of the major RDBMS distributions available. Also, these points are oriented towards developers relatively new to the SQL ecosystem and/or accessing pre-built database schemas built for a mature system. Having established that, let's get started.
Know thy data
Though this may seem like an absolute no-brainer, I cannot emphasize this point enough. I have seen a ton of simple queries take time to execute, simply because of the lack of knowledge regarding the underlying data i.e the scope of and information present in each table, the significance of each column, the primary key constraints on the tables being queried, the relation between the tables i.e are there any foreign key dependencies? What are the join columns?
Overwhelmed? Let me break it down in a few concise points. In general, it is essential to know :
The number of rows present in the base table(s) being queried.
The number of rows or the percentage of data that is expected to be fetched by the query.
The nature of data present in the table(s) being queried - some tables have static data that is rarely modified, whereas some are reflective of OLTP systems and are constantly modified or populated by incoming transactions.
The join clauses and predicates required for filtering the data if the query involves multiple tables.
This might sound daunting, and frankly some of the details may not quite be available if you are new to an organization or project and still getting your feet wet. But stuff like constraints and dependencies are available as a part of the schema metadata. Also look for any documentation like ER diagrams that may be available to understand table level details.
Let us understand the first three points with an example: Consider an ecommerce website having tables customer and customer_products. The customer table has details of each customer like Customer_id, customer_fname, customer_lname etc. The customer_products table has details of products purchased by each customer.
Customer
Primary key : customer_id
| customer_id | customer_fname | customer_lname | contact_no | from_date | gender | |
| C1 | Anne | P | 12566652 | 23-Aug-2015 | annep@xxxx.com | F |
| C2 | Bob | S | 23476287 | 20-Sep-2015 | bobs@yyyy.com | M |
Customer_products
| customer_id | product_id | date_of_purchase | payment_mode |
| C1 | P1 | 02-Jul-2020 | Debit Card |
| C1 | P2 | 02-Jul-2020 | Debit Card |
If one were to write a query to fetch the list of female customers who purchased any product till date, it would involve a join of the above tables based on customer_id with condition on the date_of_purchase column. Further, since the customer_products tables is populated for each purchase transaction, it is bound to have millions of rows for any enterprise level organisation. Any query on this table is bound to take time to fetch the desired result.
- Number of rows present in the customer_products table: ~ 5 million
- Percentage of rows being fetched: ~ half of customer table (as the condition is on the gender column) joined with the heavy customer_products table
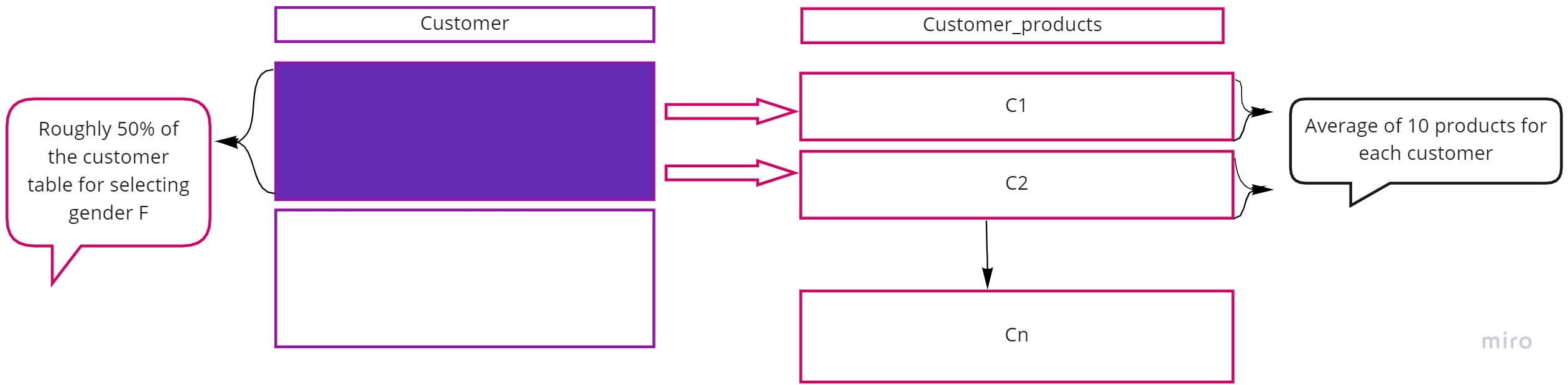
The performance becomes all the more critical for tables created for logging or historical data maintenance as they are designed to store data for every operation - for the purpose of debugging and audit. Such scenarios make it critical for the person issuing the query to have a thorough understanding of the data being queried before executing the select statement.
Beware of Unintended Cartesian Joins
Let's examine the last bullet sub-point mentioned in the previous point - regarding joins. While joining multiple tables to formulate a query, it may so happen that we skip a join clause for one of the table pairs. This results in a cartesian product of the tables being joined.
A cartesian product results when each row of the left-hand table is joined with each row of the right-hand table to yield a total of M x N rows as output, where M and N are the number of rows in the left and right hand tables respectively.
Consider this SQL statement using the same two tables above:
SELECT c.customer_id, c.fname , product_id
FROM customer c, customer_products cp;
Just on the basis of the above subset of rows taken as an example, the result will be:
| customer_id | customer_fname | product_id |
| C1 | Anne | P1 |
| C1 | Anne | P2 |
| C2 | Bob | P1 |
| C2 | Bob | P2 |
We can see that products P1 and P2, though purchased by Anne as per customer_products table have appeared in the output against Bob as well. Which is as a result of the missed join condition in the query. This can be detrimental in a query involving three or more tables and each table having a large number of rows.
The WHERE clause - No functions here
We use different SQL in-built functions to transform our output as per requirements, like NVL , UPPER , TO_DATE. While these can be used in the select clause, avoid using them in the WHERE clause while comparing column values. Consider the following query
SELECT fname
FROM customer
WHERE SUBSTR(fname,1,2)='An';
The above query fetches all the customer first names starting with the letters 'An'. Though this query will yield the desired result, it cannot be considered efficient as the database optimiser will perform a full scan of all the records in the customer table and avoid any indexes that may have been created on the fname column, which may have resulted in faster query processing. A better query for our purpose would be :
SELECT fname
FROM customer
WHERE fname like 'An%';
There could be some scenarios where it is absolutely imperative to transform the column value before comparison. For eg: If we are unsure of the case (upper/lower/title case) in which all customer first names have been stored, then we might have to resort to a query like:
SELECT fname
FROM customer
WHERE UPPER(fname) like 'AN%';
Here, it is better to create a function based index on the fname column i.e. index on UPPER(fname) instead of just fname.
More on indexes and their uses in another post
SELECT what you need, not what you want
A lot of seemingly simple queries slow down because of the number of columns specified in the select clause.
It is a good practice to limit the columns specified in the select clause to only those which serve your specific purpose. Avoid writing select * from table unless the table contains very few columns.
When it's ok not to bring ORDER to the chaos
While querying a large table(s), avoid unnecessary ORDER BY clauses if the sequence in which the column values are displayed is of no consequence to the final output.
ORDER BY clauses mandate an extra SORT operation to be performed once all the results are fetched, which greatly impacts the performance of large datasets, as sorting is a resource intensive operation if the column specified is not indexed. Even then, there can be a few circumstances where the query may be slowed down. In short, do not order unless you have to.
This brings us to the end of this short piece on improving SQL query performance. This article was intended to provide a gateway into incorporating certain practices for writing clean SQL and highlight some key factors to look out for which might be hampering your execution time. Part II of this topic will cover more such tips, including the use of indexes which have mentioned in this piece.
Till then... Happy querying!