




In continuation of the previous article on improving SQL query performance, let us examine a few table level modifications that can be made for faster output generation.
Indexes
For the uninitiated, an index is a special lookup table that is created to store a column or a subset of columns of a table, that is used by the database engine to speed up data retrieval. A general practice is to index the most frequently queried columns of the table so the database can use the index as a quick lookup table instead of scanning the entire table. Further, the data in the index is sorted (ascending order by default) at the time of index creation which further improves the performance of queries requiring sorted data.
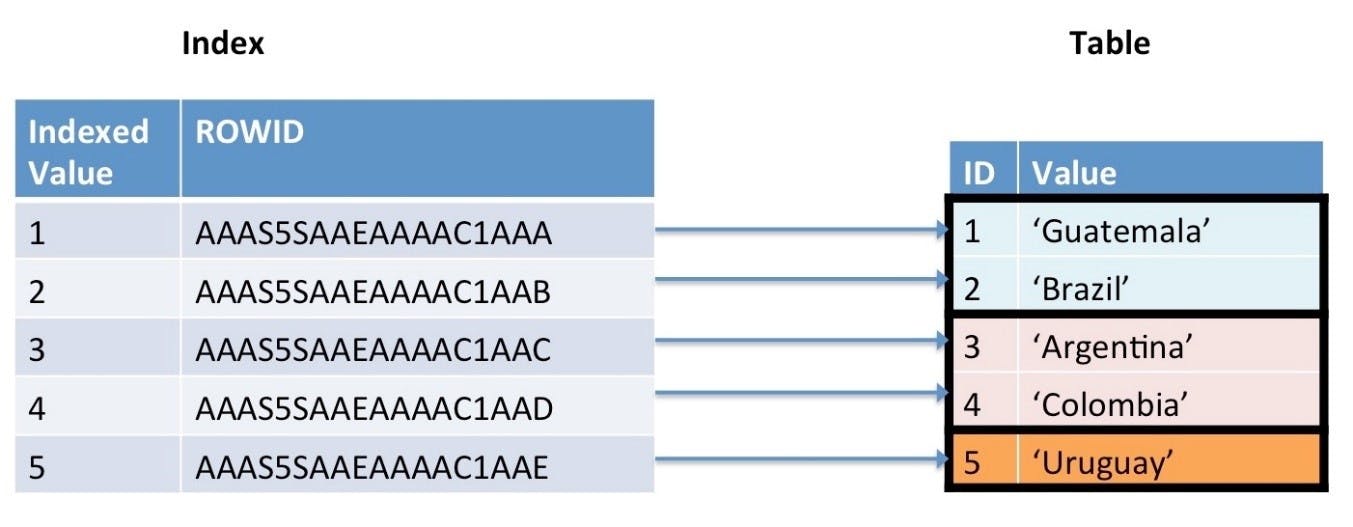
Image Source : Toad World Blog
Creating an index on a table is the most common and sure-fire means of improving a query performance. Then why hold off this topic till Part II of the post on SQL query optimisation?
That's because index creation is a slightly more nuanced topic that requires a proper knowledge of the table data, entity relationships and an idea of the columns that will be frequently searched. It is also important to remember that creating too many indexes can introduce an overhead and might degrade the performance of DML operations(INSERT/UPDATE/DELETE) on the respective tables if overdone. Above all, as an SQL developer, you may or may not have the privileges to create indexes at will in a traditional RDBMS used for storing production data for the reasons just outlined.
Which begs the question - Can we leverage the use of previously created indexes for our queries in situations where we have no control on the index manipulation?
The answer is YES and below are a few guidelines for using indexes to our advantage. Before proceeding, a quick look at composite indexes. Composite indexes are indexes built on a combination of two or more columns which are likely to be queried together.
- Check if you can rewrite your query to use the indexed columns as a part of your WHERE clause. For instance, consider the following table subset of the customer_products_date table having a composite index on the column (month_c,year_c)
| customer_id | product_id | date_of_purchase | month_c | year_c |
| C1 | P5 | 31-Dec-2020 | 12 | 2020 |
| C1 | P2 | 30-Dec-2020 | 12 | 2020 |
| C2 | P1 | 25-Nov-2020 | 11 | 2020 |
If we had to write a query to find the purchases done in a particular month of a year, it would be prudent to use the indexed month_c and year_c column instead of using the date_of_purchase column as follows:
SELECT customer_id,product_id
FROM customer_products_date
WHERE month_c=12
AND year_c=2020;
- Leverage composite indexes to query individual columns too
Consider a table employee_dept table with the following columns and having a composite index on (employee_id, dept_id).
| Employee_id | Dept_id | Salary | Date_of_joining |
| E1 | 1 | 50000 | 20-Jan-2020 |
| E2 | 2 | 20000 | 21-Feb-2021 |
Any query using the employee_id column will make use of the index created instead of scanning the entire table as the employee_id is the leading (i.e first) column in the composite index.
What if we issue a query using only the dept_id column for filtering records, like below?
SELECT employee_id, dept_id
FROM employee_dept
WHERE dept_id=10;
Well, in that case, Oracle ( From release 9i onwards), performs something called as an index skip scan which probes the index multiple times instead of a simple index look-up for fetching the results. While this may take a little longer than a separate index created on the dept_id column, it is still faster that going through the entire employee_dept table. It also reduces the number of indexes that must be created and maintained, not to mention preventing the corresponding space wastage incurred for building multiple indexes.
The PARALLEL Hint
Hints in Oracle are directives that instruct the database engine to use certain techniques to effectively process the query. Though the use of hints is controversial, to say the least, as they have a tendency to meddle with the optimiser and its ability to choose the most efficient way to process a query, there are some Hints - like the PARALLEL hint which is commonly used for faster fetches.
The parallel hint is mentioned as a part of the SELECT clause, enclosed in comments and preceeded with the + sign, with an argument for mentioning the DOP - degree of parallelism.
Consider the following dept table joined with the above mentioned employee_dept table for fetching the location of each employee
Dept table
| Dept_id | Dept_name | Location |
| 1 | Accounts | Mumbai |
| 2 | HR | Kolkata |
Following is the query using inner join
SELECT /*+ PARALLEL(4)*/ employee_id, location
FROM employee_dept e, dept d
WHERE e.dept_id=d.dept_id;
The parallel hint in the query directs the optimiser to process the execution of this query in parallel. Which means the multiple steps that go into a query execution - like scanning a table/index , joining the rows of the first table with those of the second table etc will be divided among multiple concurrent threads and performed simultaneously and hence speed up the process.
The DOP is the argument supplied to PARALLEL, 4 in our case. It determines the number of parallel threads into which the processing will be divided. Hence, it is important to provide a reasonable value for the same. To begin with, use DOPs between 4-12 and check how it improves performance.
Filter early
While using aggregate functions like count, max, min and avg, in case the final result only requires only a subset of the entire data to be displayed, it is best to filter early.
In other words, specify your condition in the WHERE clause instead of in the HAVING clause after the GROUP BY.
For eg, if we were to write a query to fetch the number of employees working in each dept using the employee_dept , but only for the dept ids between 1 to 10, then instead of
SELECT dept_id, count(dept_id) as count_dept
FROM employee_dept
GROUP BY dept_id
HAVING dept_id between 1 and 10;
the following query will run faster.
SELECT dept_id, count(dept_id) as count_dept
FROM employee_dept
WHERE dept_id between 1 and 10
GROUP BY dept_id;
This is because the filtering of relevant records will be done before the intensive GROUP BY computation. The HAVING clause, on the other hand will filter records once the aggregation has been done for all the records, resulting in performance degradation.
Gather statistics
In Oracle or any RDBMS for that matter, there is an underlying optimiser that evaluates every query fired against the database and prepares multiple possible execution plans (A detailed break-down of the steps that would be involved in the processing of the query with an estimate of the resource consumption at each step). The Oracle CBO (Cost based Optimiser) in particular, calculates the overall cost of each candidate plan. The cost is simply an estimate of the number of physical I/O operations that could be required to fetch the data. The optimiser then chooses the plan with the least cost as the means to process a query.
This digression into the world of execution plans was necessary to understand the gravitas of the necessity to gather statistics. Whenever the CBO calculates and evaluates the cost of a plan, it does so by using some pre-compiled statistics regarding the tables involved in the query, namely :
The number of rows in the table
Average row length
Number of distinct column values
Number of NULLs in each column
The data distribution of the columns (histogram)
Index statistics like the number of leaf nodes in an index
among other details.
Over time, these statistics may become stale, specially if the underlying tables undergo lots of data modifications, inserts or deletes. These operations affect most of the factors listed above like the row count, the average row length and column data distribution. Hence, the need to gather fresh statistics from time-to-time.
The gathering of statistics can be periodically scheduled with the help of a DBA, but just in case we want to gather the stats for a particular table.
Syntax
EXEC DBMS_STATS.GATHER_TABLE_STATS ('<Owner>', '<Table name>');
Sample:
EXEC DBMS_STATS.GATHER_TABLE_STATS ('hr', 'employees');
Though the GATHER_TABLE_STATS procedure can take many more arguments, the two mentioned above are the mandatory ones.
Executing your query after this can help improve the performance as the optimiser now has accurate data with which to evaluate the plans.
It's all part of the plan
Finally, if you are interested in diving deeper into the process of SQL optimisation and find yourself issuing and tuning many a long-running query, it is best to learn to read the EXPLAIN PLAN output.
Before running the query, we can generate the explain plan of a statement, which will provide the plan that the optimiser will eventually choose during the actual query processing. This is the "winner" plan out of all the candidate plans generated by the optimiser for query execution - which in case of Oracle is the plan with the least cost.
EXPLAIN PLAN FOR SELECT * from employee_dept;
SELECT plan_table_output
FROM table(DBMS_XPLAN.DISPLAY('PLAN_TABLE'));
Though the calculation and the choice of the ideal plan is done by the optimiser, it is worthwhile being able to read a query's execution plan to derive insights about :
The type of scans being used (Full table scan / Index scan)
The means used for joining multiple tables (nested loops/ hash joins)
The number of rows returned at each step
Any cartesian joins done due to missed join conditions
among other things. This will help us as developers take possible corrective measures and decisions regarding columns to index, tables to partition and whether any unnecessary table being used in the query can be removed for better performance.
This brings us to the end of the two-part series on SQL performance tuning. Do bear in mind that we have barely scratched the surface with these steps and each point mentioned above is a topic worth exploring on it's own.
Also when it comes to performance tuning, there are no set rules or commandments which ensure perfect results. It is an iterative process of observing, modifying, poring over explain plans and settling on trade-offs before achieving satisfactory results - as there can be multiple factors affecting query execution.
Hope this helped. Stay tuned for more code samples and deep dives into the world of SQL and performance tuning.